
Junyu Chen
chenjydl2003 [at] gmail (dot) com
I am an undergraduate student in Yao Class, Tsinghua University.
My current research interests lie in the algorithm-system co-design for accelerating contemporary AI foundation models. I was a research intern in MIT HAN Lab under the supervision of Professor Song Han. Previously, I worked on 3D visual perception and human-robot interaction with Professor Li Yi in Tsinghua University.
Email / Google Scholar / GitHub / Twitter / Linkedin
Awards
- 2024 Yao Award (Silver Medal)
- 2023 SenseTime Scholarship
- 2024 Tsinghua University Overall Excellence Scholarship
- 2023 Tsinghua University Overall Excellence Scholarship
- 2022 Tsinghua University Overall Excellence Scholarship
- 2021 Tsinghua Xuetang Talents Program Scholarship
- 2021 Tsinghua University Freshman Scholarship
Competition Awards
- 2020 Gold medal in the 14th Asia and Pacific Informatics Olympiad (APIO)
- 2020 First prize in the National Olympiad in Informatics (NOI) in China
- 2019 First prize in the National Olympiad in Informatics (NOI) in China
News
- Jan 22 2025: DC-AE and SANA are accepted by ICLR 2025.
- Feb 29 2024: GenH2R is accepted by CVPR 2024.
Selected Projects
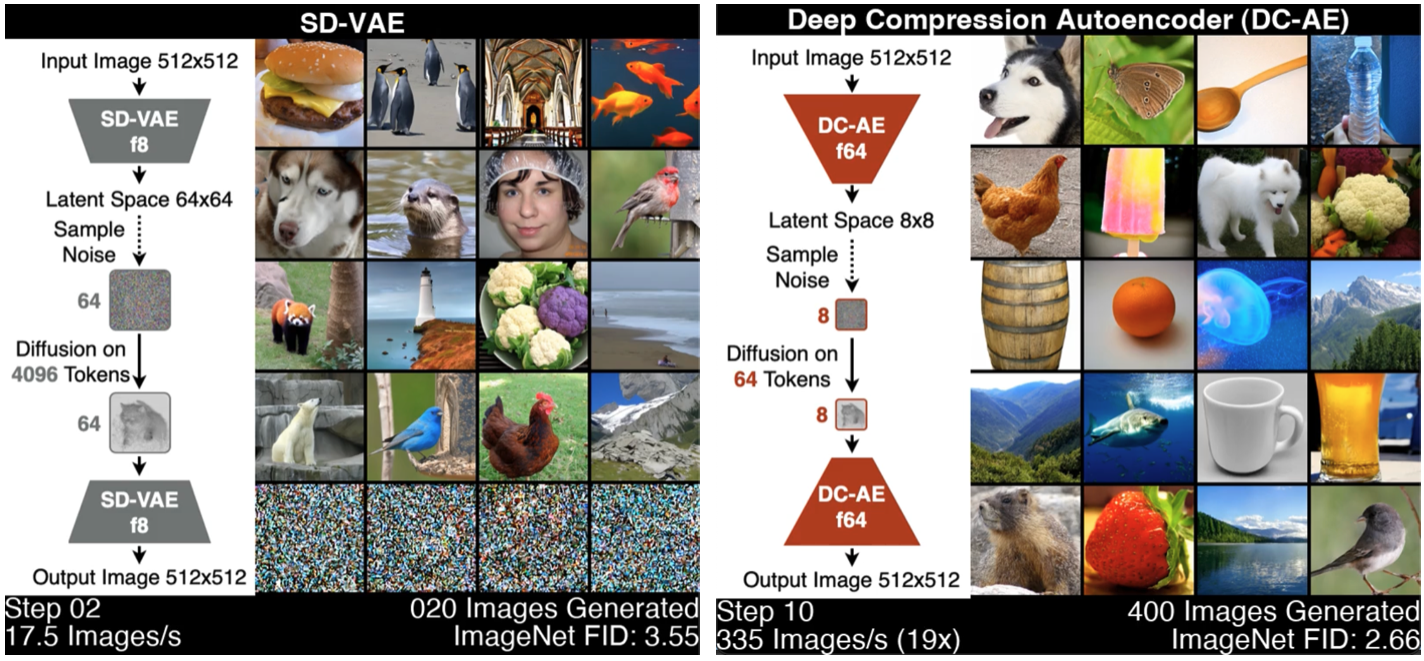
Deep Compression Autoencoder for Efficient High-Resolution Diffusion Models
DC-AE is a new autoencoder family for accelerating high-resolution image generation. DC-AE solved the reconstruction accuracy drop issue of high spatial-compression autoencoders, improving the spatial compression ratio up to 128 while maintaining the reconstruction quality. It dramatically reduces the token number of the latent space, delivering significant training and inference speedup for latent diffusion models without any performance drop.

SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
SANA is a text-to-image framework that can efficiently generate images up to 4096×4096 resolution. Sana can synthesize high-resolution, high-quality images with strong text-image alignment at a remarkably fast speed, deployable on laptop GPU. Core designs include: (1) Deep Compression Autoencoder (2) Linear DiT: we replace all vanilla attention in DiT with linear attention, which is more efficient at high resolutions without sacrificing quality. (3) Decoder-only text encoder: we replaced T5 with decoder-only small LLM as the text encoder and designed complex human instruction with in-context learning to enhance the image-text alignment. (4) Efficient training and sampling: we propose Flow-DPM-Solver to reduce sampling steps, with caption labeling and selection to accelerate convergence.

GenH2R: Learning Generalizable Human-to-Robot Handover via Scalable Simulation, Demonstration, and Imitation
GenH2R a framework for learning generalizable vision-based human-to-robot (H2R) handover skills. The goal is to equip robots with the ability to reliably receive objects with unseen geometry handed over by humans in various complex trajectories. We leverage large-scale 3D model repositories, dexterous grasp generation methods, and curve-based 3D animation to create an H2R handover simulation environment named GenH2R-Sim. We further introduce a distillation-friendly demonstration generation method that automatically generates a million high-quality demonstrations suitable for learning. Finally, we present a 4D imitation learning method augmented by a future forecasting objective to distill demonstrations into a visuo-motor handover policy.
Academic Services
- Serve as a reviewer for ICLR, CVPR